


























































Rippling and its affiliates do not provide tax, accounting, or legal advice. This material has been prepared for informational purposes only, and is not intended to provide or be relied on for tax, accounting, or legal advice. You should consult your own tax, accounting, and legal advisors before engaging in any related activities or transactions.
Eliminating Data Skew in Flink: 27% Faster Processing and $1M in Annual Savings

In this article
Jeffrey Chuc, Senior Software Engineer on Rippling's Query and Data Platform team, faced a critical bottleneck in Rippling's MongoDB-to-Aurora CDC pipeline on Apache Flink.
To solve this, the team re-architected the system to a Partition-Keyed Architecture. This change boosted average CPU utilization to 90%, cut total processing time by over 27%, and is projected to save approximately $1 million in annual costs. Read below to find out how.
Introduction
Rippling’s analytics stack ingests data from dozens of products and hundreds of data models, replicating it in real-time from sources like MongoDB into query-optimized stores like Aurora and Iceberg. Our domain-specific query layer, Rippling Query Language (RQL), sits on top of this pipeline to power reporting and visualizations across the platform.
In this post, we'll focus on the MongoDB-to-Aurora pipeline in this system that we built on Apache Flink, and how we eliminated a critical bottleneck by re-architecting the way work is distributed across Flink subtasks. We'll walk through the problem, the technical changes required to solve it, and the performance and cost improvements we saw on the other side.
Background
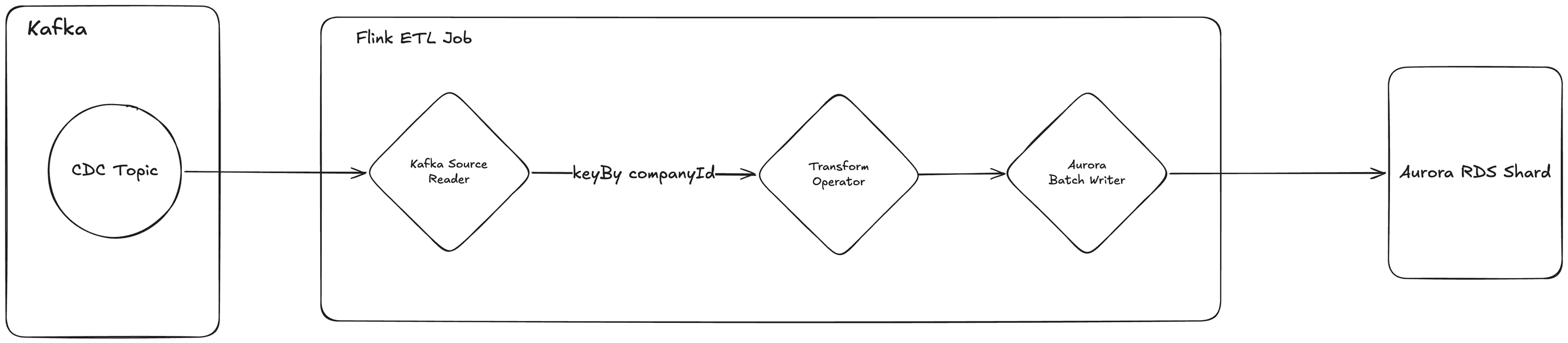
Figure 1. Flink ETL data flow with keyBy(companyId).
Our Flink Change Data Capture (CDC) architecture consumes messages from Kafka and distributes them across subtasks within the Flink ETL job. Each subtask processes a batch of messages for a single company and writes the results to one Aurora RDS shard. An Aurora RDS Shard is a horizontally scaled instance of an Amazon Aurora relational database where each shard holds data for a subset of companies to spread query and storage load across multiple database instances.
The Problem: The "Hot Subtask" Bottleneck
Our legacy Flink job distributed work by keying on companyId (our main “tenant” identifier). While convenient, this tied the performance of an entire subtask to the data volume of a single tenant. Large tenants would saturate a single subtask to 100% CPU, while subtasks serving smaller tenants sat idle. These "hot subtasks" became bottlenecks for the entire pipeline. We could not utilize the full CPU capacity, leading to elevated processing latency and wasted infrastructure spend.
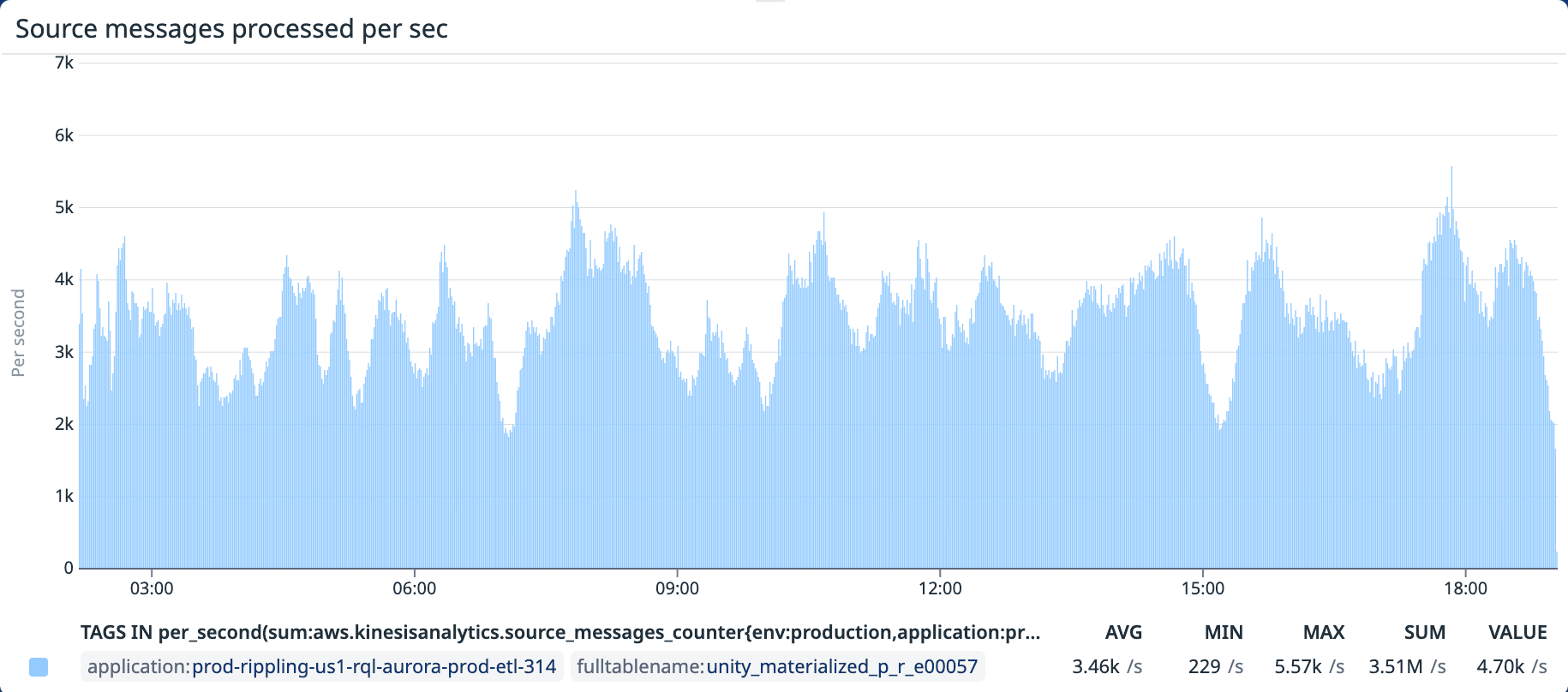
Figure 2. Messages processed per second — old keyBy(companyId) architecture. The high variance in message throughput across subtasks is a byproduct of uneven distribution.
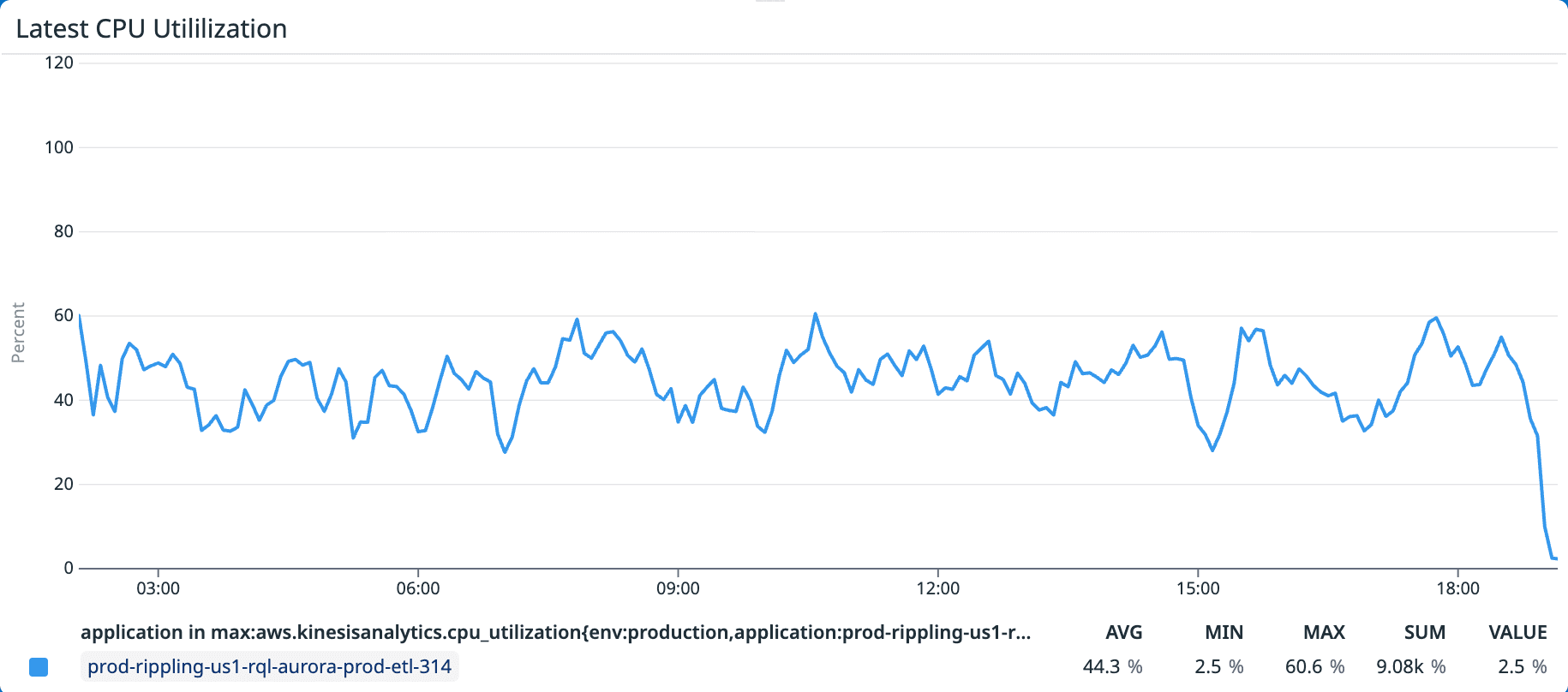
Figure 3. Average CPU utilization — old keyBy(companyId) architecture. Most subtasks sit idle while a few are saturated, capping average utilization at 44%.
The Brainstorm
For 95% of our use cases, the pipeline performed exactly as expected. But a handful of MongoDB collections with bursty, high-volume write patterns exposed the limits of our companyId-keyed architecture. A single large tenant could flood one subtask while the rest of the cluster sat idle, and there was no way to redistribute that load after the fact.
We knew Kafka was already distributing messages evenly across partitions, so the obvious move was to key on partition instead of company. The problem was that we had no way to pin each Flink subtask to a specific Kafka partition.
We spent the next week experimenting with several approaches, including Flink's experimental reinterpretAsKeyedStream API, but nothing gave us the deterministic control we needed. Then, while digging into Flink's internal implementation of keyBy, we noticed it was using MurmurHash3 under the hood. What if we just reversed it?
The Solution: Partition-Keyed Architecture

Figure 4. Example data distributions with different keyBy keys.
Kafka already distributes messages evenly across partitions. By re-keying our Flink job on sourcePartitionId instead of companyId, we can take advantage of that even distribution. This rewrite required three major technical changes:
Deterministic "InverseMurmur" Routing
Challenge: Flink’s keyBy operator uses MurmurHash3 internally to assign keys to subtasks. Naively keying on sourcePartitionId, a small sequential integer, produces severe clustering in the key-group assignment. With 10 Kafka partitions and 10 available subtasks, MurmurHash3 mapped all 10 partition IDs onto just 5 subtasks, with 60% of the total load concentrated on only 2 of them. The other 5 subtasks sat completely idle.
Solution: We implemented an inverse MurmurHash function that pre-computes a synthetic key guaranteed to hash to a specific subtask. This creates a deterministic 1:1 mapping between each Kafka source partition and a Flink subtask, ensuring perfectly even distribution across the cluster.
How it Works: MurmurHash3 is a non-cryptographic hash built entirely from reversible 32-bit integer operations: bit rotations, XORs, and multiplications by odd constants (which have modular multiplicative inverses). By applying each step in reverse order, we can compute the unique input that produces any desired output hash. For a given sourcePartitionId, the inverse function generates an integer key that, when Flink's keyBy hashes it internally, resolves to exactly that partition's target subtask.
Trade-offs: While relying on the reversibility of an internal hashing algorithm is generally discouraged, we chose the inverse-hash approach for its simplicity and predictability over alternatives. We have implemented robust regression testing to alert us immediately if Flink's internal hashing logic changes.
Custom Windowing and Deduplication Operator
Challenge: Under the old architecture, batch sizes were determined before deduplication. Duplicate messages inflated the batch count, so by the time duplicates were removed, the actual batches sent to Aurora were consistently undersized. This wasted write capacity and increased the number of round trips to the database.
Solution: We implemented a custom KeyedProcessFunction that deduplicates messages before batching. The operator buffers incoming records in a Flink MapState, keyed by record ID, and keeps only the record with the highest Kafka offset for each key. When the buffer reaches the configured batch size or a timeout fires, it flushes a fully packed, deduplicated batch downstream. This ensures every batch sent to Aurora is maximally utilized, reducing round trips and maximizing write throughput.
Concurrent Batch Writes to Aurora
Background: Our pipeline was originally built on Apache Pinot, which worked well for its early use cases: queries against smaller datasets with pushdown-friendly filters. But as we shifted toward broader reporting, we hit a fundamental mismatch. Pinot's scatter-gather model is built for high-throughput aggregations, not for fetching hundreds of megabytes of raw data to join with external sources before aggregating. This turned Pinot's Brokers into a data-shuffling layer that pinned at 100% CPU and regularly crashed with OOM errors. Aurora was an unconventional choice for an analytical workload, but our benchmarks showed Postgres matched Pinot's performance for our dataset sizes. Aurora gave us stability, predictable memory management, and the maturity of the Postgres ecosystem. For truly massive models, we’ve moved to Iceberg instead. Unlike Pinot, Aurora doesn't handle horizontal scaling internally, so we shard across multiple Aurora instances ourselves, routing traffic using a sharding key, primarily companyId.
Challenge: When we keyed by companyId, each subtask handled a single company per batch, so every batch mapped to exactly one Aurora shard. The writer was built around this assumption. With the new partition-keyed architecture, each subtask processes messages from many companies, meaning a single batch can contain records destined for several different Aurora shards. The existing writer had no mechanism to handle this.
Solution: We replaced the writer with AuroraBatchWriter, a concurrent writer that groups records within a batch by their target Aurora shard, then issues parallel upserts across all target shards using a thread pool. Each shard gets its own thread, so multi-shard batches are written in a single pass rather than sequentially, shard by shard.

Figure 5. Messages processed per second — new keyBy(sourcePartitionId) architecture.

Figure 6. Average CPU utilization — new keyBy(sourcePartitionId) architecture.
We benchmarked the new architecture using a fixed dataset (3.5M messages). The new architecture utilizes on average 90% of the CPU (up from 44%), indicating we have successfully eliminated the bottleneck and are fully utilizing the hardware.
As shown in Figure 6. we see the processed messages per second go down towards the end of the graph, this is due to the fact that we are completing processing on partitions and the overall messages processed per second will go down as this occurs.
Performance Benchmark Results
Old Architecture | New Architecture | % Change | ||
|---|---|---|---|---|
Throughput (msg/sec) | Average | 3,430 | 4,750 | 38.48% |
Max | 5,570 | 5,630 | 1.08% | |
CPU Utilization | Average | 44.0% | 90.1% | 104.77% |
Max | 60.6% | 100.0% | 65.02% | |
Processing Time (hours) | Total | 17.0 | 12.4 | -27.24% |
Table 1. Performance Results of Old Architecture vs New Architecture.

Figure 7. Messages processed per second — old vs new architecture side by side.
When comparing the old vs new architecture message throughput in Figure 7 we can see the improvement in processing consistency while processing the same dataset. The new architecture processes messages at a higher average message per second with a lower deviation between max and average msg/s. We also saw a ~27% improvement in processing time as we were able to process the same data set in 12.4 hours down from 17 hours.
Business Impact
The technical optimizations translated directly into operational stability and significant cost reductions:
Spike resilience: CDC traffic spikes scoped to a single tenant are now distributed across all subtasks rather than choking a single one, dramatically reducing tail latency during high-volume events.
Infrastructure reduction: The efficiency gains allowed us to scale down Flink jobs across all environments.
Cost savings: Across all environments, we realized savings of approximately 80% a month. At our current scale, that’s approximately $84,000/month or $1 million per year.
Conclusion
This project addressed the most acute bottleneck in our MongoDB-to-Aurora pipeline, but it's just one piece of a broader effort across the Query and Data Platform team. We're now applying similar thinking to our other ingestion pathways — optimizing how we replicate into Iceberg, improving freshness guarantees, and scaling the infrastructure that powers RQL across Rippling's growing product surface.
If you're excited about stream processing, data infrastructure, and solving distributed systems problems that directly impact millions of users, we'd love to hear from you.
Disclaimer
Author

Jeffrey Chuc
Senior Software Engineer
Jeffrey is a Senior Software Engineer on Rippling's Query and Data Platform team, building real-time stream processing pipelines. He focuses on automating scalable ETL systems and data infrastructure that power Rippling's analytics products.
Hubs
See Rippling in action
Increase savings, automate busy work, and make better decisions by managing HR, IT, and Finance in one place.